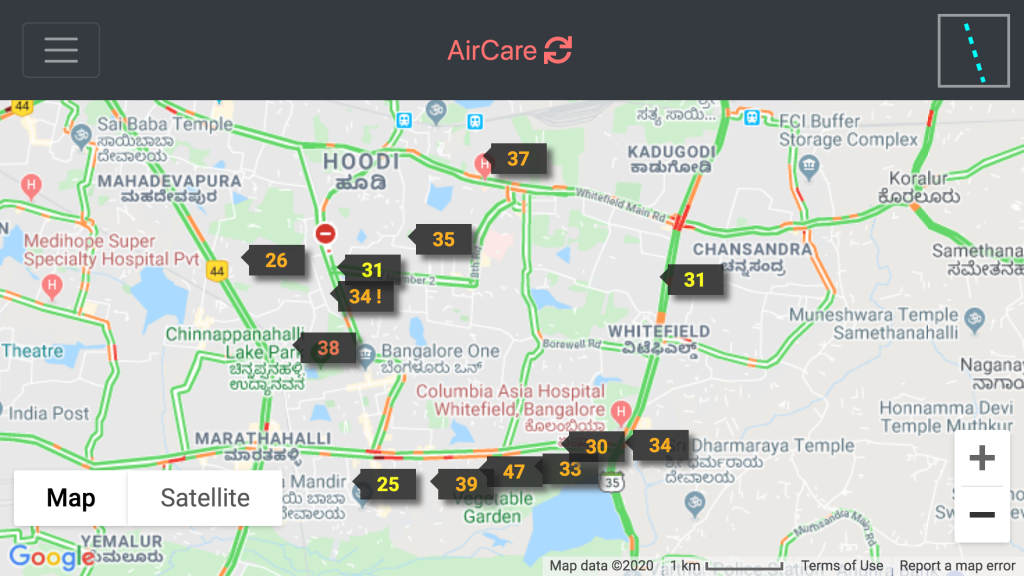
This article describes the assessment of air quality around Whitefield (Bangalore, India) for the period Aug 2018 to Dec 2019 based on the data from 13 citizen managed low cost realtime air quality monitors and one government manual monitor. For the assessment, we will be using the PM2.5 (particulate matter of size 2.5 microns or below measured in μg/m3) measurements done by 14 PM2.5 monitors at various locations around Whitefield.
For an in depth analysis, we will be using data from an AirCare monitor at Ferns Paradise and compare with the data from the AirCare monitor at Windmills.
PM2.5 are particles or droplets of size 2.5 microns or less are a major part of polluted air and is associated with various negative health effects. There is no safe limit for PM25 and the WHO guideline value is 10 µg/m3 for annual average. Long term exposure to these particles cause increased rates of heart disease, stroke, lung diseases, kidney disease, and diabetes. For 10 µg/m3 increase in PM2.5 the life expectancy reduces by one year. Exposure to 10 µg/m3 of PM2.5 is equivalent to smoking half a cigarette per day. You can read about PM2.5 and its harmful effects here.
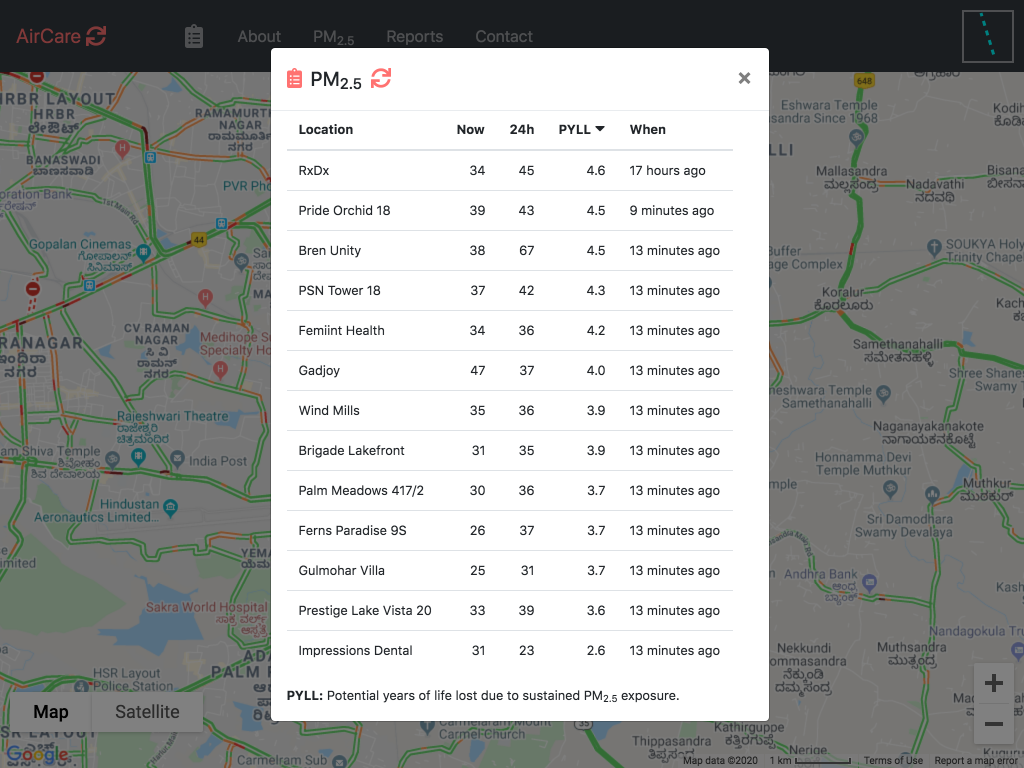
https://aircare.mapshalli.org Figure 2: PM2.5, last 24 hours averages, and loss of life expectancy @ Jan-18-2020 10:30AM
Findings & Analysis
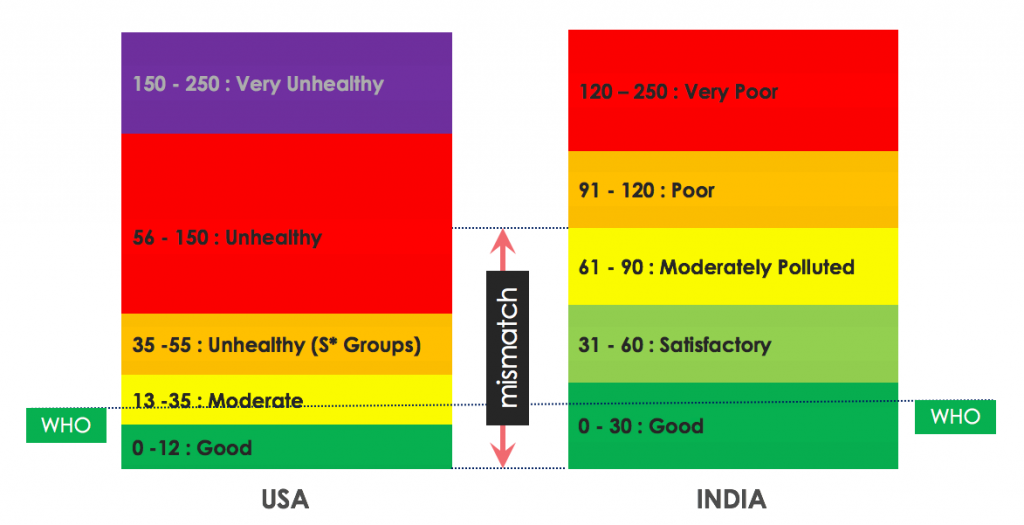
Why do we want to use the USA air quality standards in our analysis?
In the analysis described in this article, we have used the US air quality standards instead of the India air quality standards.
Figure 3: Mismatch of air quality assessment between WHO/USA vs Indian standards. Values displayed are for PM2.5 in µg/m3
Indian air quality standards are very relaxed. For example, an 60 µg/m3 24 hour PM2.5 exposure is considered euphemistic Satisfactory, whereas as per USA standards it is considered Unhealthy!
60 µg/m3 of PM2.5 is 6x the WHO guidelines, equivalent to smoking 3 cigarettes a day, and losing of 6 years of life!
In India, the air quality is reported via air quality index that is in the range (0-500). Air quality index is more suitable to report a single index number when considering many pollutants like PM2.5, PM10, NO2, etc. All the research reports that analyze health effects are based on raw PM2.5 values averaged to 24 hours and yearly. We have used raw PM2.5 number for the analysis. The air quality assessment is based on USA air quality standards are described here.
Yearly snapshot
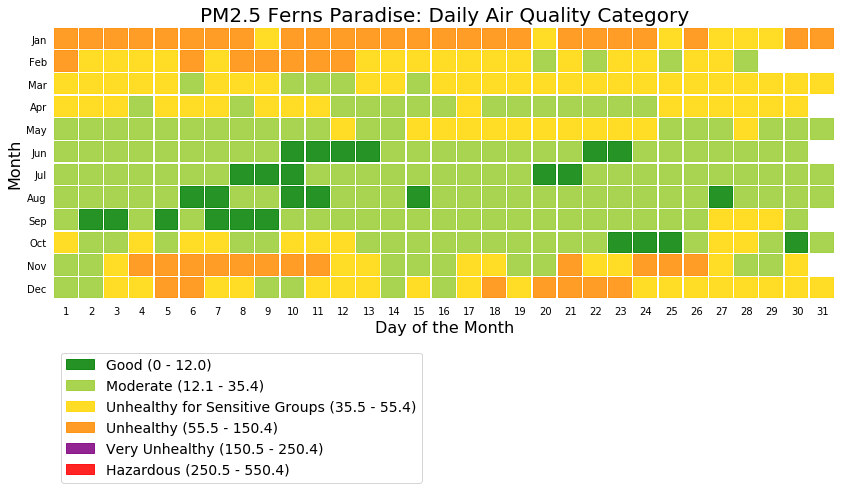
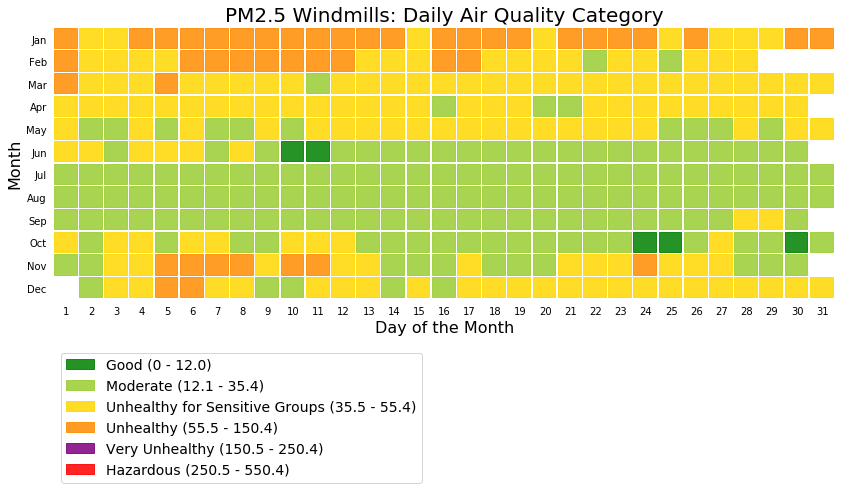
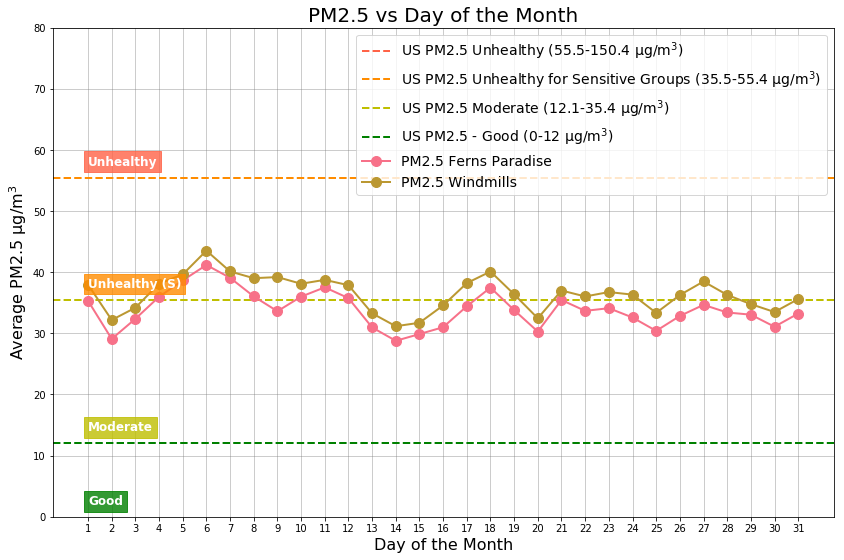
The following picture shows the daily air quality assessment for two Whitefield locations for everyday of the year.
Figure 4: Ferns Paradise – Daily air quality assessment as per USA air quality standards – PM2.5 µg/m3
Figure 5: Windmills – Daily air quality assessment as per USA air quality standards – PM2.5 µg/m3
The above two figures shows that Ferns Paradise had more Good air quality days when compared to Windmills. Note the high number of Unhealthy air quality level days during the months of January and February.
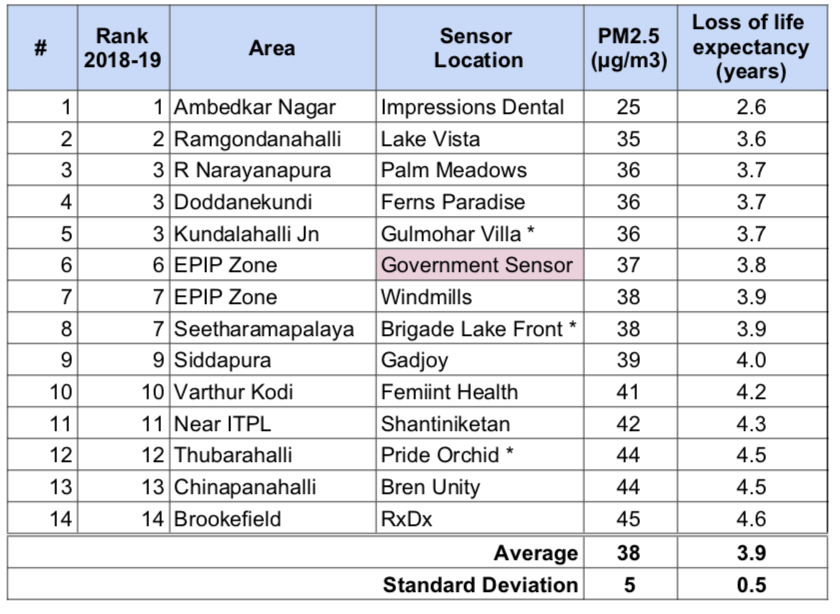
Table 1: Air quality ranking and loss of life expectancy
The table below shows the best air quality rank, Aug 2018 to Dec 2019 period PM2.5 averages, and loss of life expectancy for Whitefield locations.
Table 1: Ranking, PM2.5 and loss of life expectancy * Based on partial data
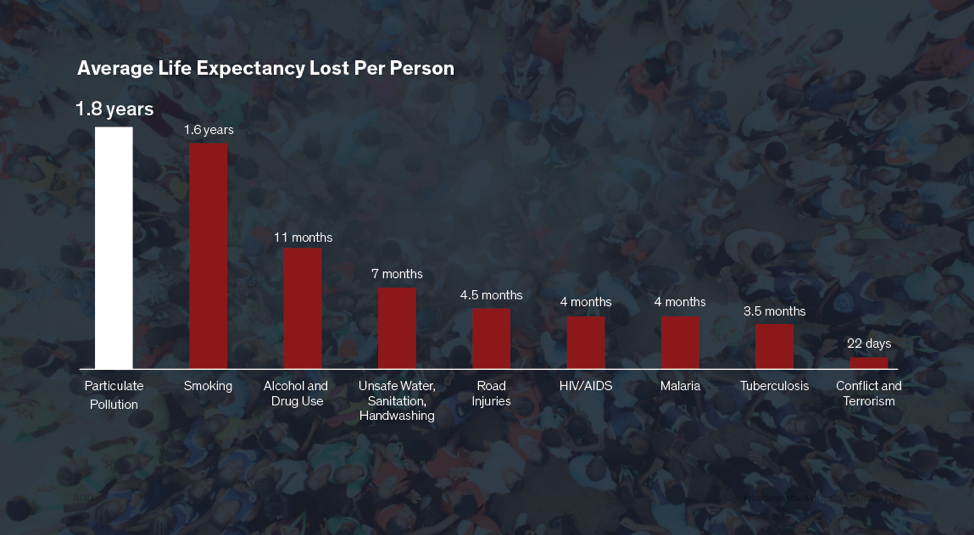
The PM2.5 levels are 3.8x times of that of WHO guidelines and fall in the Unhealthy for Sensitive Groups USA air quality assessment category,meaning that members of sensitive groups may experience health effects and the general public is not likely to be affected. The following table shows a comparison of average life expectancy lost due to various causes.
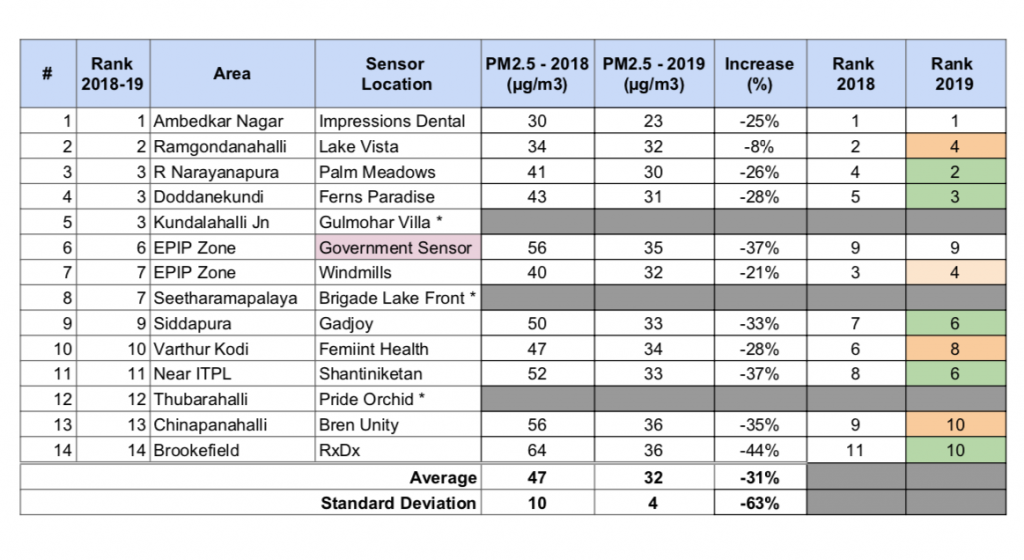
Table 2: 2018 to 2019 reduction in PM2.5 pollution
The table below shows the yearly PM2.5 pollution level changes from 2018 (Aug-Dec) to 2019 (Aug-Dec):
Table 2: 2018 – 2019 changes in PM2.5 and ranking of locations * Do not have data for the comparison
From 2018 to 2019, the air quality has improved from Unhealthy for Sensitive Groups to Moderate category. Moderate means that the air quality is acceptable; however, for some pollutants there may be a moderate health concern for a very small number of people who are unusually sensitive to air pollution. All location except Ramagondanahalli show good improvement in air quality.
The reduction in PM2.5 levels can be attributed to the following known significant factors:
24% increase in Wind Speed from 2018 to 2019.
54% increase in rain from 2018 to 2019.
Graphite India Private Ltd factory partial shutdowns during the months of Oct-Dec 2018 and permanent closing down in Feb 2019.
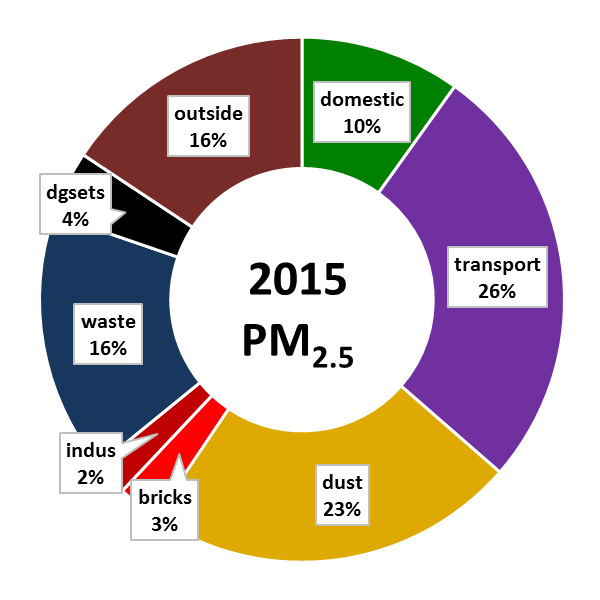
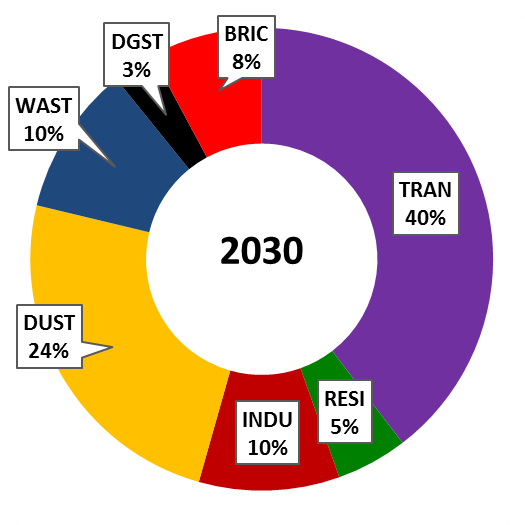
There is an unquantified increase in pollution due to increased number of vehicles, open waste burning, construction, and road dust. The following chart shows the source contributions for the year 2015 and 2030 (projected) from http://www.urbanemissions.info/india-apna/bengaluru-india/.
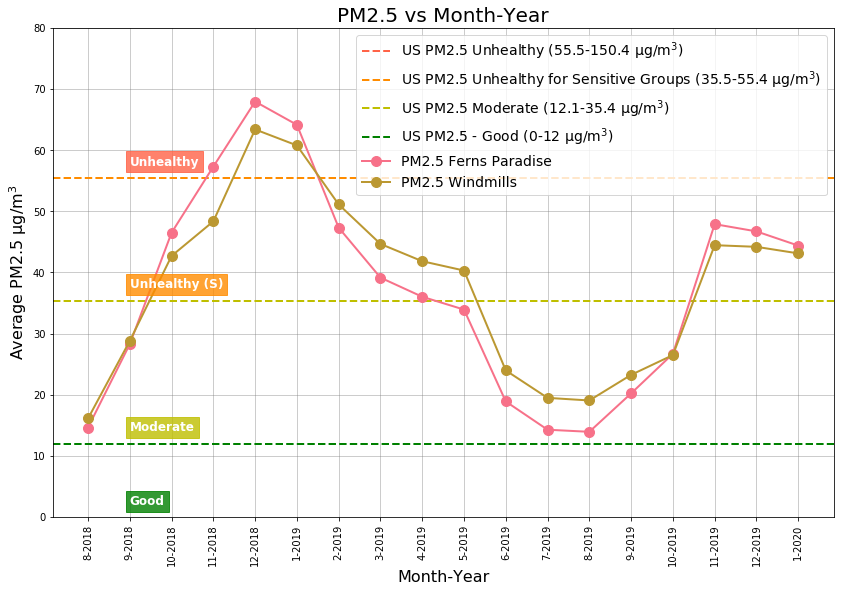
Figure 9: PM2.5 History from 11-Aug-2018 to 11-Jan-2020
Monthly Averages
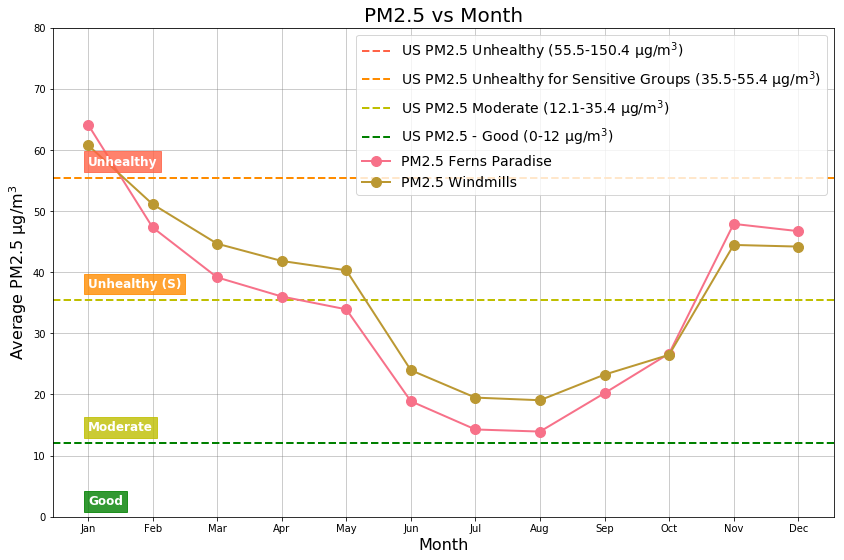
Figure 10: Monthly Averages
The Unhealthy (64 µg/m3) air quality level is found during January. Top three months with Unhealthy for Sensitive Groups (47 µg/m3) air quality levels are: November, December, and February. Top three months with Moderate (16 µg/m3 ) air quality levels are : June, July, and August.
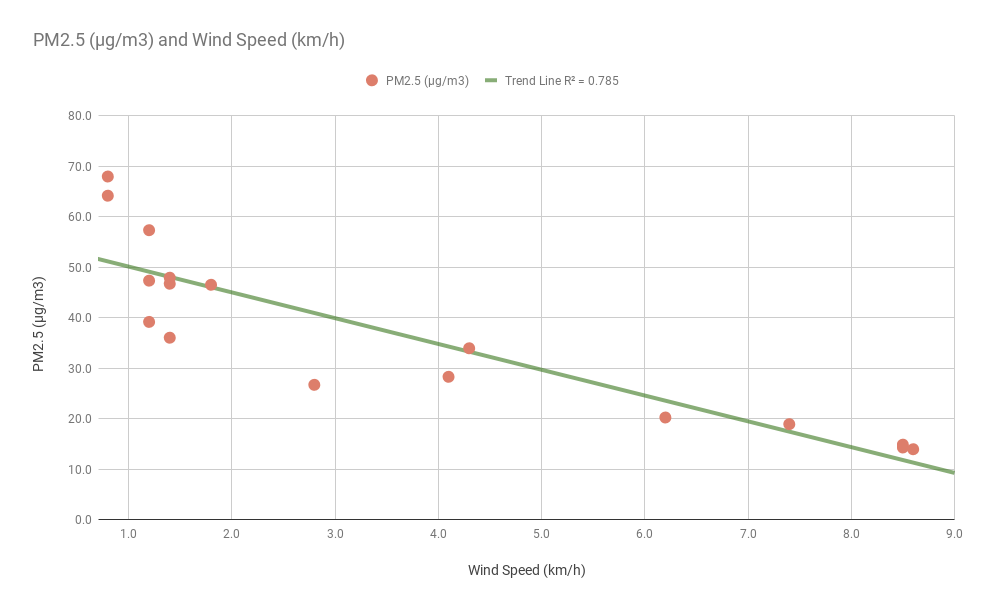
During the months of June to September, the south west monsoon has a monthly average wind speed greater than 6 km/hr that effectively transports away the particulate matter reducing the pollution. During the same time, the monsoon rain also washes away the particulate matter but to a lesser extent. The monthly average wind speed (0.2 km/hr ) and the rain fall is at their lowest in January causing the particulate matter to linger close to the source.
Figure 11: Relationship between PM2.5 pollution and Wind speed
Wind speeds greater than 6 km/hr significantly reduces the PM2.5 pollution to levels below 20 µg/m3. Large number of open lands being converted buildings would reduce the wind speed and hence would increase the pollution levels.
Day of the Month
Figure 12: Day of the Month
Days of the month with Unhealthy for Sensitive Groups (40 µg/m3 ) air quality levels are: 4th, 5th, and the 6th. Top three days of the month with Moderate (29 µg/m3) air quality levels are: 2nd, 14th, and the 15th.
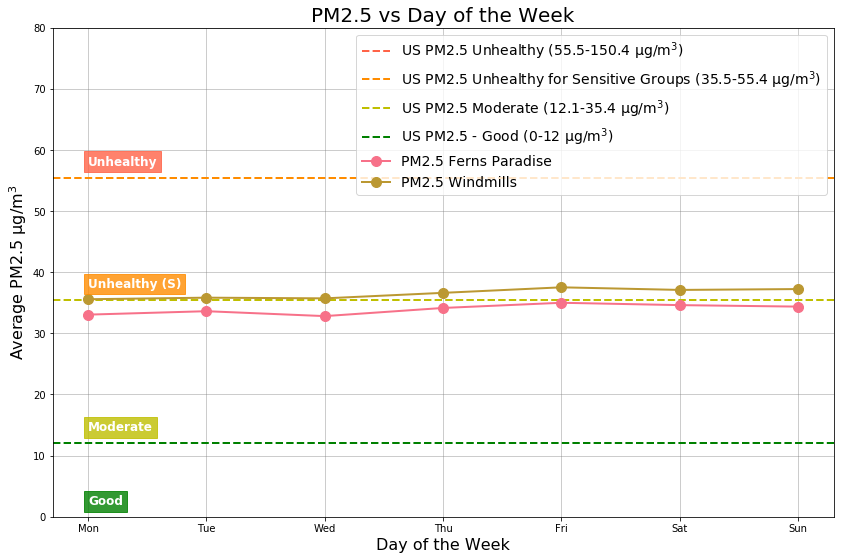
Day of the Week
Figure 13: Day of the Week
The PM2.5 pollution levels remain the same independent of the day of the week.
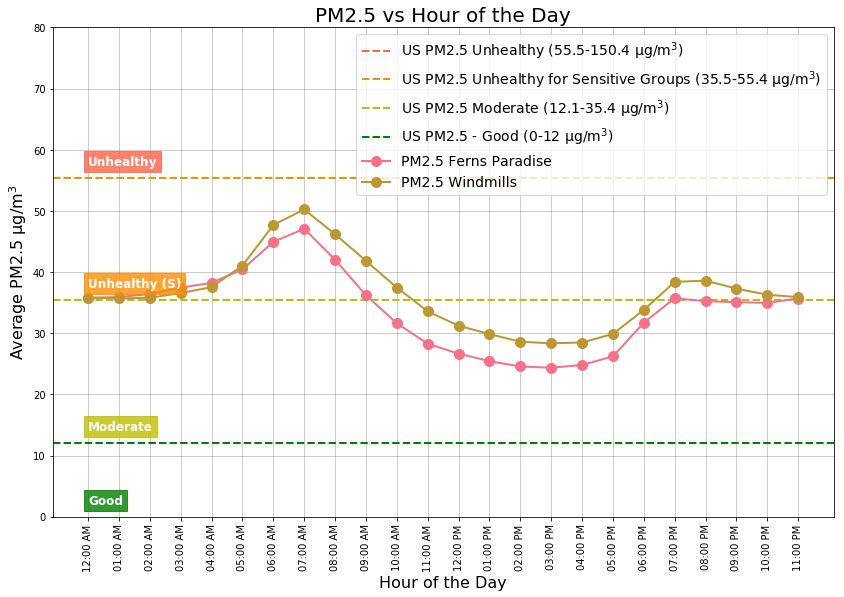
Hour of the Day
Figure 14: Hour of the Day
Hours of the day with Unhealthy for Sensitive Groups (45 µg/m3) air quality are: 06:00AM – 08:00AM. Hours of the day with the Moderate (25 µg/m3 ) air quality levels are: 01:00PM – 03:00PM.
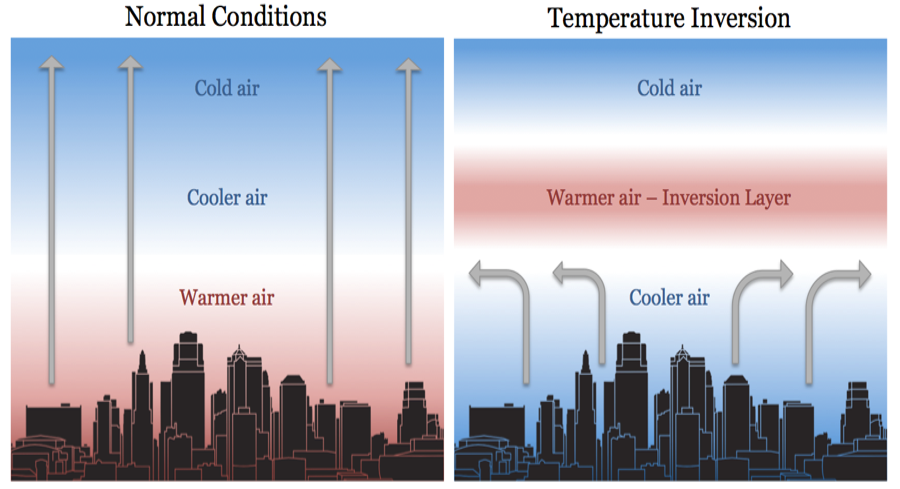
The air that is closer to the earth is warmer and denser than the air above. The higher you go the air becomes colder and thinner. The air temperature decreases by ~1 degree centigrade for every 100m increase in altitude. The warmer air that closer to the ground rises transporting any particulate matter.
During the winter months (Nov, Dec, and Jan) the skies are clear, the air is calm and stable, and the nights are longer. The winter sun, low in the sky supplies less heat to the earth’s surface; this heat is quickly radiated cooling air closer to the ground. A less dense warm air moves in to create a warm air cap/lid called the Inversion Layer, as shown in Figure 15.
Figure 15: Temperature Inversion
During the winter early morning hours, this inversion layer traps the pollutants along with the cooler air rich in moisture and is called the smog as shown below in Figure 16. This is the primary cause of high pollution during the winter mornings.
Figure 16: Smog trapped over the city of Almaty, Kazakhstan during a temperature inversion.
Once the Sun heats up the land and the air later in the day, the inversion layer is broken and the pollutants are carried away.
Recommendations
Summary
Annual PM2.5 pollution levels across Whitfield (Bangalore) is estimated to be around 38 µg/m3. This is 3.8x times of the WHO guideline of 10 µg/m3. An estimated 3.9 years of life expectancy is lost due to PM2.5 pollution; this is 2x of the years lost due to smoking!
Mother nature has helped in reducing pollution by 31% year over year through winds and extended monsoon rain. Citizens have played a role in shutting down multiple polluting industries around Whitefield.
The number vehicles, road dust, and open waste burning continue to rise unabated every year.
Citizens
Citizens should become more aware of air quality standards and apply pressure to the government to follow WHO guidelines and adopt international standards. Become aware of who can influence actions to improve air quality. Residents need to actively promote walkability in the neighborhood and public transport through increasing number of BMTC Buses, METRO, Sub-urban rail.
Citizens should eliminate their outdoor activities like walking, playing, and exercising when the air quality levels are Unhealthy for Sensitive Groups or worse: be aware of the poor air quality till 08:00AM. You can get a real time air quality for your location (or closer) at https://aircare.mapshalli.org. You can reduce the indoor air pollution level to less than 10 µg/m3 by installing and operating an indoor air purifier.
From a policy front, Indian government should come up a realistic air quality standards aligned with WHO standards and adopt best practices from other countries.
Karnataka State Pollution Control Board (KSPCB)
Whitefield, the technical powerhouse of India just has one manual government air quality monitor! It is high time to replace the manual government monitor installed in EPIP, Whitefield with a real time continuous monitor that provides timely information to the citizens.
BBMP, local Corporators, and the local MLA
Include improvement of air quality in your manifesto and in the ward improvement plans.
Ensure that the roads are cleared off dust and improve road infrastructure to prevent resuspension of road dust. Increase street cleaning using mechanized cleaners and manually remove dust from the roads and footpaths
Proper disposal of garbage and penalizing garbage burning will also help.
Acknowledgments
We thank various individuals and home owner associations for hosting the 12 AirCare air quality monitors and one Purpleair monitor. They also spend their energy on a continuous basis to keep the monitors up and running. Rahul Bedi provides us with critical weather data for analysis.
A list of individuals whom we want to thank are: Manoj (RxDx), Dr. Sunitha Maheshwari (RxDx), Clement Jayakumar (Ferns Paradise), Ajit Lakshmiratan, (Gulmohar), Zibi Jamal (Wind Mills), Ramakrishnan (Palm Meadows), Srinivas Ganji (Brigade Lakefrnont), Vivekanand (Gadjoy), Dr. Jagadish Prasad (Femiint Health), Mithun (PSN), Mukesh (Bren Unity), and Rahul Bedi (Pride Orchid).
Epilogue
How good are the low cost air quality monitors?
The questions people always ask are the following: how good are the low cost sensors, have they been calibrated and recalibrated, will the data be used and accepted by government including the courts?
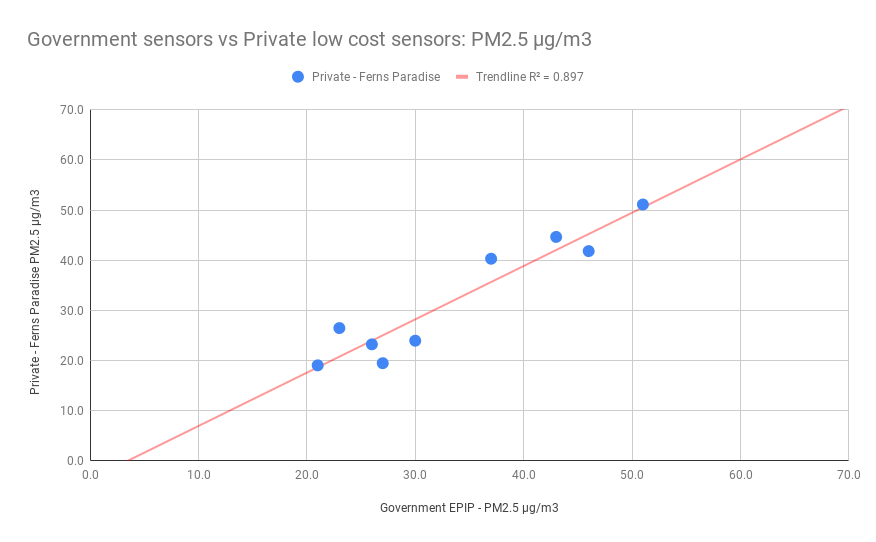
The following figure shows correlation between the government monitor and one citizen air quality monitor.
Figure 17: High correlation (R2=0.9) between government and private monitors Data shown is monthly PM2.5 in µg/m3
Government including the courts will not accept data from low cost air quality monitors operated by citizens. We have shown that the data collected by large number of low cost monitors is as good as the expensive government monitors. The citizens air quality monitors provide better real time data and are able to capture the variations from location to location more effectively. We hope the data can be used in discussions to influence government to install more government real time air quality monitors.
Do you know someone who lives in the Whitefield area who goes for morning or evening walks? Why are we recommending that you should not take morning or evening walks? What is the best time to walk then?
Based on the air quality analysis based on the data from March-01-2018 to Sep-30-2018, from Purple Air sensor located at Thubarahalli we found the following:
Air quality is the worst between 06:00AM – 08:00AM and between 07:00PM – 08:00PM.
Air quality is worse during the months of March and April; it becomes better during June and July.
Saturday has the worst air quality and Monday is the best day.
13th of every month has the best air quality and 31st has the worst air quality.
Are you concerned about air quality and pollution? Want to know how to plan your day so that you are exposed to least amount of pollution? Please continue reading… The following topics are covered in detail:
What is PM2.5 and how does it relate to pollution?
Where to view PM2.5 data for Whitefield, Bangalore?
Data analysis of air pollution from March-01-2018 to Sep-30-2018 and findings.
How does pollution change month by month?
What are the best and worst air quality days in a month?
Which day of the week is the most polluted?
Which hours of the day is the most and least polluted?
What is PM2.5 and how does it relate to pollution?
The term PM2.5 refers to fine particles or droplets of size 2.5 microns are less. This is 30 times smaller than an human hair. These particles are so small that they can reach your blood stream through the lungs. These particles come from vehicle exhausts, , vehicle brakes, construction, road dust, and fuel burning. Long term exposure to these particles cause increase rates of chronic bronchitis, reduced lung function, lung cancer, kidney disease, and diabetes.
PM2.5 is measured in µg/m3 (micro grams in a cubic meter).
PM2.5 Standards
WHO PM2.5 standards
WHO recommended guidelines is 10µg/m3 for annual average and 25 µg/m3 for 24 hour average. There is no safe level of PM2.5.
USA PM2.5 standards
The USA standard for PM2.5 (µg/m3 24 hours), category, and health impacts are shown below.
0 to 12.0 – Good
Air quality is considered satisfactory, and air pollution poses little or no risk.
12.1 to 35.4 – Moderate
Air quality is acceptable; however, for some pollutants there may be a moderate health concern for a very small number of people who are unusually sensitive to air pollution.
35.5 to 55.4 – Unhealthy for Sensitive People
Members of sensitive groups may experience health effects. The general public is not likely to be affected.
55.5 to 150.4 – Unhealthy
Everyone may begin to experience some adverse health effects, and members of the sensitive groups may experience more serious effects.
150.5 to 250.4 – Very Unhealthy
Health alert: everyone may experience more serious health effects.
250.5 to 500.4 – Hazardous
Health warnings of emergency conditions. The entire population is more likely to be affected.
Where to view current values of PM2.5 in Whitefield, Bangalore?
You can view the latest value (PM2.5 short term) and 24 hour average values at:
Data analysis of air pollution from March-01-2018 to Sep-30-2018 and key findings
Mr. Rahul Bedi has been operating an air quality and weather station at Pride Orchid, Whitefield. The sensor data is available at purpleair.
We have analyzed over 222,216 sensor readings and found the following:
Air quality is the worst between 06:00AM – 08:00AM and between 07:00PM – 08:00PM.
Air quality is worse during the months of March, April, and Sep; it is better during June and July.
Saturday has the worst air quality and Monday is the best day.
13th of every month has the best air quality and 31st of the month has the worst air quality.
How does pollution change month by month?
Although the air quality is becoming better over the months, it is expected to become worse after the monsoon is over and during the Diwali season.
What are the best and worst air quality days in a month?
After all, 13th is not an unlucky day, it is the least polluted day in a month. Don’t step out of the house on the 31st.
How does pollution change by the day of the week?
How does pollution change by the hour of a day?
The best time to walk is during the lunch hour! Avoid those early morning walks!
Conclusion
Hope the above data analysis can help to plan your days and hours better and avoid air pollution. You can contribute by becoming a host of a community air quality sensor. Read more about it here.
In this previous article, I explain the transfer learning approach to train a deep neural network with 94% accuracy to diagnose three kinds of eye diseases along with normal eye conditions. In this article, I will explain a different and a better approach to transfer learning to achieve >98% accuracy at 1/10th of the original training speed.
In this new article, I will provide a background of the previoust implementation and the drawbacks of the previous approach. Next, I will provide an overview of the new approach. Rest of the article will explain the new method in detail with annotated Python code samples. I have posted the links at the end of the article for you to try out the methodology and the new model.
Part 1 – Background and Overview
Transfer learning – using a fully trained model as a whole
The previous article utilized the following method of transfer learning.
Use InceptionV3 model previously trained with imagenet dataset. Remove the fully connected layers and the classifier at the end of the network. Let us call this model, the base model.
Lock the base model so that it does not get trained with the training images.
Attach few fully connected layers and a 4 way softmax classifier at the end of the network that have been randomly initialized.
Train the network by feeding the images randomly for multiple iterations (epochs).
This model was inefficient for the following reasons:
Could not achieve state of the art accuracy of 96% but could achieve only 94%.
Best performing model was obtained after 300 epochs.
Each epoch took around 12 minutes to train as the image data was fed through the whole InceptionV3 model plus the new layers in every epoch.
The whole training effort run took 100 hours! (4 days).
Long training time per epoch made it difficult to explore different end layer topologies, learning rates, and number of units in each layer.
Transfer learning – extract features (bottlenecks), save them and feed to a shallow neural network
In the previous approach, each image was fed to the base model and the output of the base model was fed into the new layers. As the base model parameters (weights) were not updated, we were just doing the same computation in the base model in each epoch!
In the new approach, we use the following methods:
First, we feed all the images (training and validation) to extract the output of the base InceptionV3 model. Save the outputs, i.e, features (bottlenecks) and the associated labels in a file.
Next, build a shallow neural network with the following layers:
Convolution 2d layer that can take the saved features as input.
Batch normalization layer to increase speed and accuracy.
Relu activation.
Dropout layer to prevent overfitting.
Dense layer with 4 units (corresponding to 4 output classes) with softmax activation
Use adam optimizer with learning rate of 0.001.
Next, feed the saved features to the shallow network and train the model. Save the best performing model found during training and reduce the learning rate if the validation loss remains flat for 5 epochs.
While making predictions, feed the image first to the InceptionV3 (trained in imagenet), and feed its output to the shallow network. Use the first convolutional layer in the shallow network to create occlusion maps.
This approach gave the following results:
Best performing model at 99.10% accuracy
Repeatable accuracy at >98%
Each epoch take around 1.5 minutes compared to 12 minutes as before.
Requires only 50 epochs (75 minutes) when compared to 500 epochs (100 hours) to achieve convergence.
Model size has reduced from 84MB to 1.7MB
In the rest of the article I will explain the new method in detail with annotated Python code samples. I have posted the links at the end of the article for you to try out the methodology and the new model.
Part 2 – Implementation
Extract features using imagenet trained InceptionV3 model
Import the required modules and load the InceptionV3 model
fromkeras.applications.inception_v3importInceptionV3,conv2d_bnfromkeras.modelsimportModelfromkeras.layersimportDropout,Flatten,Dense,Inputfromkerasimportoptimizersimportosimportnumpyasnpfromkeras.preprocessing.imageimportImageDataGeneratorimporth5py
from __future__ importprint_functionconv_base=InceptionV3(weights='imagenet',include_top=False)
Import the required modules including conv2d_bn function from Keras applications. This handy conv2d_bn function create a convolution 2d layer, batch normalization, and relu activation.
We then load the InceptionV3 model with imagenet weights without the top fully connected layers.
Extract features by feeding images and save the features to a file
Using Keras image generator functionality we process sample_count images with batch_size images in a batch. The output is stored in a h5 file as values with the following keys:
batches : Total number of batches. Each batch will have batch_size number of images and the last batch might have less than batch_size images.
features-<batch_number> (Example: features-10): extracted features of shape (100, 8, 8, 2048) for batch number 10. Here is the 100 is number of images per batch (batch_size) and (8, 8, 2048) is the feature map. This is the output of mixed 9 layer of InceptionV3.
labels<-batch_number> (Example: labels-10): extracted labels of shape (100, 4) for batch number 10. Here 100 is the batch size and 4 is the number of output classes.
Here, we setup two generators to read features and labels stored in h5 files. We have renamed the h5 files so that we don’t overwrite by mistake during another round of feature extraction.
The input shape should match the shape of the saved features. We use Dropout to add regularization so that the model does overfit data. Model summary is shown below:
Typically, one would use only fully connected layers. Here, we use convolutional layer so that we can visualize occlusion maps.
Train the model, save the best model and tune the learning rate
# Setup a callback to save the best modelcallbacks=[ModelCheckpoint('./output/model.features.{epoch:02d}-{val_acc:.2f}.hdf5',monitor='val_acc',verbose=1,save_best_only=True, mode='max',period=1),ReduceLROnPlateau(monitor='val_loss',verbose=1, factor=0.5,patience=5,min_lr=0.00005)]history=model.fit_generator( generator=train_generator, steps_per_epoch=train_steps_per_epoch,validation_data=validation_data, validation_steps=validation_steps,epochs=100,callbacks=callbacks)
Using ModelCheckpoint keras callback, we want to save the best performing model based on validation accuracy. This check and save is done for every epoch (period parameter).
Using ReduceLROnPlateau keras callback we monitor validation loss. If the validation loss remains flat for 5 (patience parameter) epochs, apply a new learning rate by multiplying the old learning rate with 0.5 (factor parameter) but never reduce the learning rate below 0.00005 (min_lr parameter).
If everything goes well, you should have a best models saved in the disk. Please refer to the github repo for the code to display the accuracy and loss graphs.
Import the required modules and load the saved model
importosimportnumpyasnpimportkerasfromkeras.applications.inception_v3importInceptionV3fromkeras.preprocessing.imageimportImageDataGenerator,load_img,img_to_arrayfromkeras.modelsimportload_modelfromkerasimportbackendasKfromioimportBytesIOfromPILimportImageimportcv2importmatplotlib.pyplotaspltimportmatplotlib.imageasmpimgfrommatplotlibimportcolorsimportrequests
#set the learning phase to not trainingK.set_learning_phase(0)base_model=InceptionV3(weights='imagenet', include_top=False)
model=load_model('output/model.24-0.99.hdf5')
We need to load the InceptionV3 imagenet trained model as well as the best saved model.
Evaluate the model by making predictions and viewing the occlusion maps for multiple images
# Utility functionsclasses=['CNV','DME','DRUSEN','NORMAL']# Preprocess the input# Rescale the values to the same range that was used during training defpreprocess_input(x):x=img_to_array(x)/255.returnnp.expand_dims(x,axis=0)# Prediction for an image path in the local directorydefpredict_from_image_path(image_path):returnpredict_image(load_img(image_path,target_size=(299,299)))# Prediction for an image URL pathdefpredict_from_image_url(image_url):res=requests.get(image_url)im=Image.open(BytesIO(res.content))returnpredict_from_image_path(im.fp)# Predict an imagedefpredict_image(im):x=preprocess_input(im)x=base_model.predict(x)pred=np.argmax(model.predict(x))returnpred,classes[pred]
image_names=['DME/DME-30521-15.jpeg','CNV/CNV-154835-1.jpeg','DRUSEN/DRUSEN-95633-5.jpeg','NORMAL/NORMAL-12494-3.jpeg']forimage_nameinimage_names:path='../OCT2017/eval/'+image_nameprint(predict_from_image_path(path))grad_CAM(path)
While making predictions, we need to feed the image to the base model (InceptionV3) and then feed its output to our shallow model.
Occlusion map
The above image shows which part of the image did the model look at to make the prediction.
In this article, I showed how to feed all the images (training and validation) to extract the output of the base InceptionV3 model. We saved the outputs, i.e, features (bottlenecks) and the associated labels in a file.
We created a shallow neural network, fed the saved features to the shallow network and trained the model. We saved the best performing model found during training and reduced the learning rate if the validation loss remains flat for 5 epochs.
We made predictions by first feeding the image to the InceptionV3 (trained in imagenet), and then fed its output to the shallow network. Using the first convolutional layer in the shallow network we created occlusion maps.
This approach gave the following results:
Best performing model at 99.10% accuracy
Repeatable accuracy at >98%
Each epoch take around 1.5 minutes compared to 12 minutes as before.
Requires only 50 epochs (75 minutes) when compared to 500 epochs (100 hours) to achieve convergence.
Model size has reduced from 84MB to 1.7MB
Full source code along with the best performing model is available at:
Cell magazine publishes findings of unusual significance in any area of experimental biology, including cell biology, molecular biology, neuroscience, immunology, virology and microbiology, cancer, human genetics, systems biology, signaling, and disease mechanisms and therapeutics.
The authors have generously made the data and the code publicly available for further research. In this article, I will explain my successful attempt to recreate the results and explain my own implementation.
I have written this article for three different set of audiences:
1. General public who are interested in the application of AI for medical diagnosis.
2. Ophthalmologists who want to understand how AI can be used in their practice.
3. Machine learning students and new practitioners who want to learn how to implement such a system step by step.
A high level overview of what will be covered is listed below in the table of contents.
Table of Contents
Part 1 — Background and Overview
Optical coherence tomography (OCT) and eye diseases
Normal Eye Retina (NORMAL)
Choroidal neovascularization (CNV)
Diabetic Macular Edema (DME)
Drusen (DRUSEN)
Teaching humans to interpret OCT images for eye diseases
Teaching computers to interpret OCT images for eye diseases — Algorithmic Approach
Teaching computers to interpret OCT images for eye diseases — Deep Neural Networks
Part 2 — Implementation: Train the model
Introduction
Selection and Installation of Deep Learning Hardware and Software
Download the data and organize
Import required Python modules
Setup the training and test image data generators
Load InceptionV3 and attach new layers at the top
Compile the model
Fit the model with data and save the best model during training
Monitor the training and plot the results
Part 3 — Implementation: Evaluate the Model
Introduction
Import required Python modules
Load the saved best model
Evaluate the model for a small set of images
Write utility functions to get predictions for one image at a time
Implement grad_CAM function to create occlusion maps
Make prediction for a single image and create an occlusion map
Make predictions for multiple images and create occlusion maps for misclassified images
Part 4: Summary and Download links
Clickable table of contents below:
Part 1 – Background and Overview
Optical coherence tomography (OCT) and eye diseases
Optical coherence tomography (OCT) is an imaging technique that uses coherent light to capture high resolution images of biological tissues. OCT is heavily used by ophthalmologists to obtain high resolution images of the eye retina. Retina of the eye functions much more like a film in a camera. OCT images can be used to diagnose many retina related eyes diseases. Three eye diseases of particular interest are listed below:
Choroidal neovascularization (CNV)
Macular Edema (DME)
Drusen (DRUSEN)
The following picture shows the anatomy of the eye:
The following picture shows OCT image of an normal retina.
OCT image of a normal eye retina
Choroidal neovascularization (CNV)
OCT image of Choroidal Neovascularization (CNV)
Choroidal neovascularization (CNV) is the creation of new blood vessels in the choroid layer of the eye. CNV can create a sudden deterioration of central vision, noticeable within a few weeks. Other symptoms which can occur include color disturbances, and distortions in which straight lines appears wavy.
Diabetic Macular Edema (DME)
OCT image of Diabetic Macular Edema (DME)
Diabetic Macular Edema (DME) occurs when fluid and protein deposits collect on or under the macula of the eye (a yellow central area of the retina) and causes it to thicken and swell (edema). The swelling may distort a person’s central vision, because the macula holds tightly packed cones that provide sharp, clear, central vision to enable a person to see detail, form, and color that is directly in the centre of the field of view.
Drusen (DRUSEN)
OCT image of Drusen
Drusen are yellow deposits under the retina. Drusen are made up of lipids, a fatty protein. There are different kinds of drusen. “Hard” drusen are small, distinct and far away from one another. This type of drusen may not cause vision problems for a long time, if at all.
Teaching humans to interpret OCT images for eye diseases
How would you train humans to identify the four classes of eye conditions (CNV, DME, DRUSEN, or NORMAL) from OCT images? First, you would collect a large number of pictures (say 100) of each condition and organize them. You would then label the images (CNV, DME, DRUSEN, or NORMAL) and annotate few image of each condition to show where to look for abnormalities.
You would then show the examples, help the human to identify critical features in the image and help them classify the pictures into one of the four conditions (we’ll call them classes from now on). At the end of the training, you would them show pictures randomly and check if they can classify the images correctly.
Teaching computers to interpret OCT images for eye diseases – Algorithmic Approach
Traditionally, algorithmic approach is used for image analysis. In this method, experts study the images and identify key features in the image. Then use statistical methods to identify key features , and finally classify the whole image. This method requires many experts, lot of time and is expensive.
Teaching computers to interpret OCT images for eye diseases – Deep Neural Networks
The recent advances in machine learning using feedforward deep neural networks with multiple convolutional layers makes the training computers easy for such tasks. It is shown that the performance of neural networks increases with increase in the amount of training data available. The amount of published OCT images is limited although the authors of the papers have released 100,000 images. The neural networks tends to work better with millions of images.
The key idea is to use a neural network that has already been trained to detect 1,000 classes of images (dogs, cats, cars etc) with millions of images. One such dataset is ImageNet that consists of 14 million images. A ImageNet trained Keras model of GoogleNet (Inception v3) is already available here.
A model implements a particular neural network topology consisting of many layers. In simpler terms, the images are fed to the bottom layer (input) of the model and the topmost layer produces the output.
First, we remove the fully connected top layers (close to the output) of the model that classifies the images to 1,000 classes. Let us call this model without the top layers, the base model. We then attach few new layers to the top that classify the images into four classes of our interest: 1. CNV, 2.DME, 3. DRUSEN, 4. NORMAL.
The layers in the base model are locked and made not trainable. The base model parameters (also called weights) are not updated during training. The new updated model is trained with 100,000 OCT images with additional 1,000 images used for validation. This method is called the transfer learning. I have fully trained Keras model that achieves 94% validation accuracy and is available for anyone to download and use.
Along with the model, a simple Python method to produce occlusion maps is also available. Occlusion map shows which part of the image did the neural network paid more attention to make the decision to classify the image. One such occlusion map for DRUSEN is shown below.
Some of the benefits of using neural networks for these tasks are as follows:
The model is easy to train with existing data and retrain when new data is made available.
The model can classify new unseen images under less than a second. The model can be be embedded in the OCT machines and also can be made available as a smartphone app or a web app.
Occlusion maps help us determine which part (which features) of the image played a key role in classifying the image. These maps can be used for training humans to read the OCTs.
Using Generative adversarial network (GAN) techniques a large number synthetic image samples can be generated and used for training humans and new neural networks.
Rest of the article focuses on the step by step tutorial, annotated code samples to help you train your own model and achieve the same results of the original paper.
Part 2 – Implementation: Train the model
Introduction
In this part, I will provide step by step tutorials, annotated code samples to help you train your own model.
This part will cover the following:
Selection and installation of deep learning hardware and software.
Download the data and organize.
Writing code to train the model.
Next part will cover evaluation of the model accuracy and occlusion maps.
Selection and Installation of Deep Learning Hardware and Software
A general purpose computer or a server is not well suited for training a deep neural network that is capable of processing 100,000 images. For training purposes, I have use a customized low cost hardware with the following specifications:
Alternatively, you could use a GPU enabled Amazon Web Service (AWS) instance. The low end typically costs $0.90/hour. For the price of one month running costs, you can build your own Deep Learning Machine.
Dataset of validated OCT and Chest X-Ray images described and analyzed in “Deep learning-based classification and referral of treatable human diseases”. The OCT Images are split into a training set and a testing set of independent patients. OCT Images are labeled as (disease)-(randomized patient ID)-(image number by this patient) and split into 4 directories: CNV, DME, DRUSEN, and NORMAL.
Extract the tar file using the following command:
% tar xvfz OCT2017.tar.gz
This should create the OCT2017 folder with following sub folders: test and train. Both test and train will have sub folders named: CNV, DME, DRUSEN, and NORMAL. These bottom most folders have the gray scale OCT images.
Create another folder named eval under OCT2017. Create the required sub folders CNV,DME, DRUSEN, and NORMAL. Move few (100 images) from test and train folders to the correct eval folders finally use to evaluate the model.
Import required Python modules
The analysis code is written in python running inside Jupyter notebook. You can copy paste the code from below to cells in order and press Shift + Enter to execute the cell.
First step is to import the required modules:
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras.applications.inception_v3 import InceptionV3
from keras.layers import Dense, GlobalAveragePooling2D
from keras.models import Model
from keras import optimizers
import matplotlib.pyplot as plt
%matplotlib inline
ImageGenerator is used to rescale the image values and will be used yield batch of images during training.
GlobalAveragePooling2D and Dense will be the new set of layers that we will add to the top of the InceptionV3 model after removing existing fully connected top layers.
When you read the image file, the values of the pixels are in grey scale ranging from 0 to 255. Rescaling reduces the values to the range 0 to 1.0. It is important to remember this rescaling value during evaluation and making predictions.
The train_generator and test_generator yields 128 images in each batch of size 299×299. The number of images per batch is a function of how much memory your GPU and the main system have. The original authors have used 1,000 images per batch. The 299×299 image size is the input size required for Inception V3 model. Read more about ImageDataGenerator here.
The class_mode is set to categorial as we need the output to belong to 4 classes (CNV,DME, DRUSEN, and NORMAL).
Load InceptionV3 and attach new layers at the top
# create the base pre-trained model
base_model = InceptionV3(weights='imagenet',
include_top=False)
# Get the output layer from the pre-trained Inception V3 model
x = base_model.output
# Now, add new layers that will be trained with our data
# These layers will be randomly initialized
x = GlobalAveragePooling2D()(x)
x = Dense(64, activation='relu')(x)
predictions = Dense(4, activation='softmax')(x)
# Get the final Model to train
model = Model(inputs=base_model.input, outputs=predictions)
# Freeze the layers from the original base model so that we don't update the weights
for layer in base_model.layers:
layer.trainable = False
First, we load the InceptionV3 model with pre-trained weights for imagenet. Set include_top=False to exclude the fully-connected layer at the top of the network that outputs 1,000 classes. Instead, we will be adding our own fully connected layer that will output 4 classes using softmax.
Next, add three layers (GlobalAveragePooling2D, Dense, Dense with softmax) to the top. We use GlobalAveragePooling2D instead of a fully connected (i.e Dense) to process the output of the InceptionV3 base model. This helps in avoiding overfitting and reducing the number of parameters in the final model. The last Dense model has 4 units corresponding to the number of output classes : CNV,DME, DRUSEN, and NORMAL.
Finally, make the original InceptionV3 base model not trainable, that is, freeze the network. These weights have been already trained with imagenet. If you make these trainable, the layer parameters (weights) will get updated with large changes during the initial training making them forget the original learning. Locking the layers also makes the training faster as during back propagation these layer parameters need not be computed and updated.
Compile the model
adam = optimizers.adam(lr=0.001)
# Compile the new model
model.compile(optimizer=adam,
loss='categorical_crossentropy', metrics=['accuracy'])
Choose adam as the optimizer with learning rate set to 0.001. We are interested in minimizing loss for categorial cross entropy (meaning many categories: 4 to be specific). Train, test accuracy, and losses are the metrics that we interested in.
Fit the model with data and save the best model during training
# Setup a callback to save the best model
callbacks = [keras.callbacks.ModelCheckpoint(
'model.{epoch:02d}-{val_acc:.2f}.hdf5',
monitor='val_acc', verbose=1,
save_best_only=True, mode='max', period=1)]
# Fit the data and output the history
history = model.fit_generator(train_generator,
verbose=1, steps_per_epoch=len(train_generator),
epochs=100, validation_data=test_generator,
validation_steps=len(test_generator), callbacks=callbacks)
You want to save the best performing models during training. The best performing model is one which provides the highest validation accuracy. The output file, for example would be the following:
model.03-0.94.hdf5
03 is the epoch number and 0.94 is the validation accuracy.
To fit the data, specify the number of epochs, meaning the number of times the model will see the whole dataset. The steps_per_epoch is the number of batches of data that the model will see in one epoch. Set this to the total number of batches that the data generator will yield.
If all goes well, you should have a set of saved models, and two graphs showing the accuracy (training and validation) and loss (training and validation).
During the training, monitoring of GPU, CPU, and memory utilization is critical. In my earlier attempts, GPU ran out of memory!
GPU Utilization at 100%
Average CPU Utilization < 50%
Part 3 – Implementation: Evaluate the Model
Introduction
In this part, I’ll outline how to evaluate the trained model and make predictions using new set of images.
The analysis code is written in python running inside Jupyter notebook. You can copy paste the code from below to cells in order and press Shift + Enter to execute the cell.
First step is to import the required modules:
import os
import numpy as np
import keras
from keras.preprocessing.image import ImageDataGenerator, \
load_img, img_to_array
from keras.models import load_model
from keras import backend as K
from io import BytesIO
from PIL import Image
import cv2
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from matplotlib import colors
import requests
K.set_learning_phase(0) #set the learning phase to not training
We will be using OpenCV (cv2) for generating occlusion maps. requests library allow us to feed image referenced by an URL. It is important to set the learning phase as not training (0) to avoid errors from the keras library.
Load the saved best model
model = load_model('model.03-0.94.hdf5')
Evaluate the model for a small set of images
# Set the image generator
eval_datagen = ImageDataGenerator(rescale=1./255)
eval_dir = '../OCT2017/eval'
eval_generator = eval_datagen.flow_from_directory( \
eval_dir, target_size=(299, 299), batch_size=32, \
class_mode='categorical')
# Evaluate the model for a small set of images
loss = model.evaluate_generator(eval_generator, steps=10)
out = {}
for index, name in enumerate(model.metrics_names):
print(name, loss[index])
Write utility functions to get predictions for one image at a time
# Utility functions
classes = ['CNV', 'DME', 'DRUSEN', 'NORMAL']
# Preprocess the input
# Rescale the values to the same range that was
# used during training
def preprocess_input(x):
x = img_to_array(x) / 255.
return np.expand_dims(x, axis=0)
# Prediction for an image path in the local directory
def predict_from_image_path(image_path):
return predict_image(load_img(image_path,
target_size=(299, 299)))
# Prediction for an image URL path
def predict_from_image_url(image_url):
res = requests.get(image_url)
im = Image.open(BytesIO(res.content))
return predict_from_image_path(im.fp)
# Predict an image
def predict_image(im):
x = preprocess_input(im)
pred = np.argmax(model.predict(x))
return pred, classes[pred]
Implement grad_CAM function to create occlusion maps
def grad_CAM(image_path):
im = load_img(image_path, target_size=(299,299))
x = preprocess_input(im)
pred = model.predict(x)
# Predicted class index
index = np.argmax(pred)
# Get the entry of the predicted class
class_output = model.output[:, index]
# The last convolution layer in Inception V3
last_conv_layer = model.get_layer('conv2d_94')
# Has 192 channels
nmb_channels = last_conv_layer.output.shape[3]
# Gradient of the predicted class with respect to
# the output feature map of the
# the convolution layer with 192 channels
grads = K.gradients(class_output, \
last_conv_layer.output)[0]
# Vector of shape (192,), where each entry is the mean intensity of the gradient over
# a specific feature-map channel”
pooled_grads = K.mean(grads, axis=(0, 1, 2))
# Setup a function to extract the desired values
iterate = K.function(model.inputs,
[pooled_grads, last_conv_layer.output[0]])
# Run the function to get the desired calues
pooled_grads_value, conv_layer_output_value = \
iterate([x])
# Multiply each channel in the feature-map array by “how important this channel is” with regard to the
# predicted class
for i in range(nmb_channels):
conv_layer_output_value[:, :, i] *= \
pooled_grads_value[i]
# The channel-wise mean of the resulting feature map is the heatmap of the class activation.
heatmap = np.mean(conv_layer_output_value, axis=-1)
# Normalize the heatmap betwen 0 and 1 for visualization
heatmap = np.maximum(heatmap, 0)
heatmap /= np.max(heatmap)
# Read the image again, now using cv2
img = cv2.imread(image_path)
# Size the heatmap to the size of the loaded image
heatmap = cv2.resize(heatmap, (img.shape[1], \
img.shape[0]))
# Convert to RGB
heatmap = np.uint8(255 * heatmap)
# Pseudocolor/false color a grayscale image using OpenCV’s predefined colormaps
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
# Superimpose the image with the required intensity
superimposed_img = heatmap * 0.5 + img
# Write the image
plt.figure(figsize=(24,12))
cv2.imwrite('./tmp.jpg', superimposed_img)
plt.imshow(mpimg.imread('./tmp.jpg'))
plt.show()
The image shows which part of the image did the model look at to make the prediction.
Make predictions for multiple images and create occlusion maps for misclassified images
for i, c in enumerate(classes):
folder = './simple/test/' + c + '/'
count = 1
for file in os.listdir(folder):
if file.endswith('.jpeg') == True:
image_path = folder + file
p, class_name = predict_from_image_path(image_path)
if p == i:
print(file, p, class_name)
else:
print(file, p, class_name, \
'**INCORRECT PREDICTION**')
grad_CAM(image_path)
count = count +1
if count == 100:
continue
Here is an example of how DME was misclassified as DRUSEN output will look like:
The above picture shows how the model was confused between DME and DRUSEN. It payed attention more to the DRUSEN features instead of DME.
Part 4: Summary and download links
In this article, I have described three specific eye retinal diseases and how they can be identified from Optical coherence tomography (OCT) images along with normal eye retina.
Using transfer learning technique, I show how Keras imagenet pretrained InceptionV3 model can be trained using a large number of OCT images. We remove the top layers, add our own fully connected layers, and lock the base model to complete the training.
We save the best models during training using Keras callbacks. Using metrics we analyze the progress of the training.
Using the best saved model, we did predictions for new images and use occlusion maps to better understand the model’s behavior.
In this article, I will discuss the challenges in setting up an IoT device for the very first time and suitable methods to address these challenges.
Many IoT devices are now being shipped to end consumers and these consumers are expected to setup the devices. For example, the product AirCare IoT is a Raspberry PI based air quality sensor that needs to be setup by a consumer for the first time.
Although AirCare IoT has a built-in ethernet port, we expect the unit to be installed in a garage or a balcony where an ethernet cable is not expected to be available. The only other option is to use the Wi-Fi network. Also, no display monitor with keyboard can be connected to the IoT to allow easy configuration. Consumers expect a device such as this be easily setup using an phone app.
Expected Procedure for Configuration
A consumer would expect the following logical steps to configure the device:
If not done already, download the app from the app store.
Turn on the power for the device.
Launch the app in the phone, the device should auto recognized, perform an easy setup.
Challenges
Factory shipped IoT can’t connect to Wi-Fi network at home
In order for the above procedure to work, the IoT device should be connected to a Wi-Fi network is generally accessible from the app. This is not possible, as the IoT shipped from the factory does not know your home Wi-Fi network name and the password! The first step in the setup should logically involve providing the home Wi-Fi network and the password.
The IoT can be shipped to host an hot-spot with a known name (SSID), for example, AirCare Config, and a known password. The user can be instructed to connect their phone to this Wi-Fi network temporarily to complete the setup. The user after a successful setup can connect the phone to their regular home Wi-Fi network.
Once the network settings are available, the IoT can join the home Wi-Fi network. The IoT can fall back to be an hot-spot if the credentials are invalid or has other connectivity issues.
Can’t find the IP address of the just setup IoT
Now we face a new challenge! Once the IoT connects to the home Wi-Fi network we need to know its IP address to connect to it from the app. This process would involve accessing the Wi-Fi router admin page and inferring the IP address. We can’t expect a consumer to perform this action!
Conversely, the IoT can’t connect to the app because it does not know the IP address of the phone or the phone IP address could have changed. Also, the incoming network connections to apps are also discouraged in practice. The app would have learnt the MAC address of the IoT and can do use RARP (Reverse Address Resolution Protocol) to map MAC address to the IP address. This level of deep networking stack access is not available to the apps.
Furthermore, there is no central server like system at home that can share such information.
Solution: Use an publicly hosted custom registry that can map MAC address to the IP Address
In this solution, the IoT upon joining the home Wi-Fi network registers itself to a registry server using a well defined REST API as following:
POST http://aircare-registry.mapshalli.org/register
Parameters:
MAC address
IP address
Now, the android app can query to get the IP address as follows:
GET http://aircare-registry.mapshalli.org/register/<mac_address>
Access credentials and other parameters have been omitted for brevity. The IP address of the IoT itself is not a publicly visible IP address but private address that is only valid in the local Wi-Fi network. The session mapping of public IP address to the private address is done automatically by the local router(s) using the NAT protocol.
The app needs to manage its own MAC address to IP address table and use TTL values to intelligently query to get the IP address.
Further Study
The challenges and solutions points to the glaring gap of lack of centralized IoT management at home.